아래 예제 설명에 대한 동영상 강의는 여기 유튜브 참조
앞에서 대푯값에 대한 이론을 알아봤고, 여기서는 그 대푯값을 구하는 예제를 풀어 본다.
(여기서 사용된 소스코드 파일은, 이 페이지 하단부에 첨부되어 있음)
아래 예제 1~6번까지는, sklearn패키지에 있는 iris 데이터를 사용하시오.
데이터 불러오기 방법:
from sklearn.datasets import load_iris
iris = load_iris()
# DataFrame으로 만들기
df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris 데이터에는 다음과 같은 칼럼 존재
sepal length (cm) : 꽃 받침 길이
sepal width (cm) : 꽃 받침 너비
petal length (cm) : 꽃 잎 길이
petal width (cm) : 꽃 잎 너비
sklearn 패키지가 설치되어 있지 않다면 pip install을 통해 설치
pip install sklearnfrom sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)df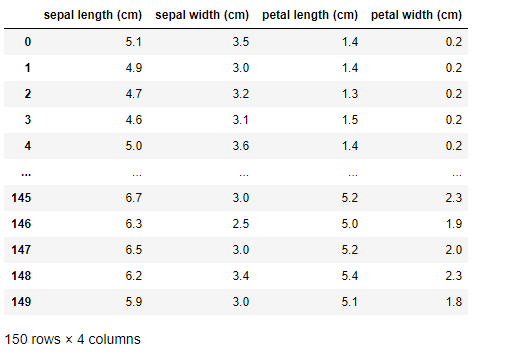
예제 1.1
iris 데이터에 있는 각 칼럼의 평균값을 구하고, 가장 평균의 큰 칼럼의 이름을 쓰시오
df['sepal length (cm)'].mean()5.843333333333334
df.mean()
예제 1.2
sepal lenght (cm) 칼럼에 대해, 최솟값과 최댓값을 제외한 데이터에 대한 평균을 구하시오.
(소숫점 세째자리에서 반올림해서 둘째 자리까지만 쓰시오)
df['sepal length (cm)'].min()4.3
s = df['sepal length (cm)']
min, max = s.min(), s.max()
s.drop(s[s==min].index, inplace=True)
s.drop(s[s==max].index, inplace=True)
s
s.mean()5.839864864864865
s = df['sepal length (cm)']
s[s.between(s.min(),s.max(), inclusive=False)].mean()5.839864864864865
예제 1.3
iris 데이터의 "sepal length (cm)"칼럼에 대해서 다음과 같은 작업을 수행하시오.
1) df를 deepcopy한 df1을 만드시오. 2) df1의 "sepal length (cm)" 데이터 중 크기가 7 이상인 값에 대해서 nan 처리하시오
3) nan 값을 제외한 나머지 데이터에 대한 평균을 구하시오
import copy
df1 = copy.deepcopy(df)
df1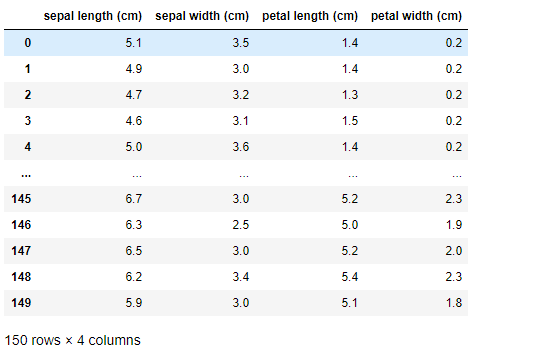
s = df1['sepal length (cm)']
s[s>=7]=None
s
s.mean()5.691970802919708
s[~s.isna()].mean()5.691970802919708
s.sum()779.8
s[~s.isna()].sum()779.8
예제 1.4
iris 데이터에서 "sepal length (cm)" 칼럼 데이터에 대해 (중앙값- 평균)값을 구하시오. (소숫점 세 째자리에서 반올림)
s = df['sepal length (cm)']
s
s.median() - s.mean()-0.04333333333333389
예제 1.5
iris 데이터에 대해서 각 칼럼 데이터의 (중앙값-평균)이 가장 큰 칼럼명을 구하시오.
df.median()
df.mean()
df.median() - df.mean()
예제 1.6
iris 데이터에 다음 작업을 수행하시오.
1)df를 deepcopy한 df2를 만드시오
2)df2의 모든 값을 정수형으로 바꾸시오
3)각 칼럼의 최빈값중 가장 큰 최빈값을 가지는 칼럼을 구하시오
4)"sepal length (cm)"칼럼 데이터 중 2번째로 많은 빈도를 가지는 값을 구하시오
import copy
df2 = copy.deepcopy(df)
df2 = df2.astype(int)
df2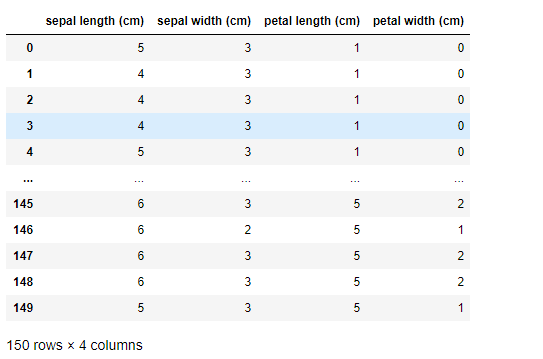
df2.mode()
df2['sepal length (cm)'].value_counts()
첨부 파일:
-끝-
다음 글: 1.2 산포 (이론, 풀이)
'Information > 통계강의' 카테고리의 다른 글
| 1.3 데이터 스케일링 (이론) (0) | 2021.02.13 |
|---|---|
| 1.2 산포 (이론, 예제 풀이) (0) | 2021.02.12 |
| 1.1 대푯값 (이론) (0) | 2021.02.12 |
| 1. 통계량 (0) | 2021.02.12 |
| 0. 강의 개요 (0) | 2021.02.12 |


