아래 쪽 설명에 대한 강의는 여기 유튜브 동영상을 보세요.
대푯값은 자료를 대표하는 값이다.
여러 개의 값으로 구성된 자료에 대해서, 그 전체 값들을 아울러서 대표하는 값이다.
대푯값으로 가장 많이 쓰이는 것은 평균이다.
그 외에도 중앙값, 최빈값, 최솟값, 최댓값들이 자료를 대표하는 하는 값으로 쓰일 수 있다.
A) 평균 (Mean)
평균은 해당 자료의 무게 중심에 해당하는 값이다. 자료들의 값을 무게로 본다면, 무게들의 중심에 해당하는 값이다.
전체 평균은 전체 값을 더한 후, 전체 개수로 나누면 된다. 이는 모집단이건 표본집단이건 꼭 같다. (뒤에 설명되는 분산의 경우는 모집단과 표본집단에 대한 수식이 다르다.)
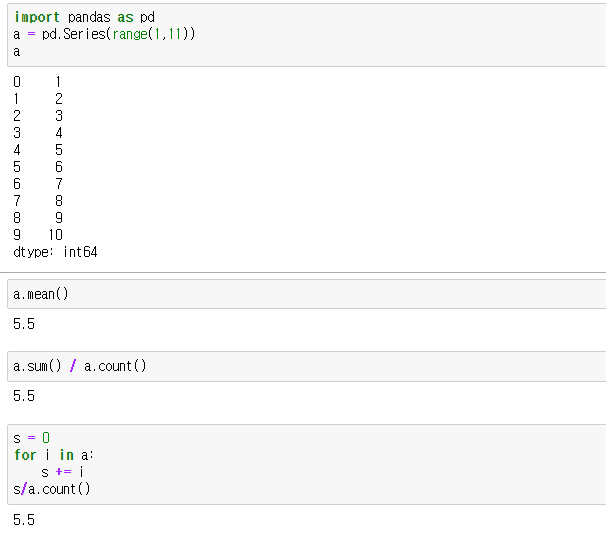
Pandas에서 평균은 mean 함수로 구할 수 있다. (정확하게 얘기하면 Series 클래스의 mean 함수)

평균을 구하는 예제를 알아보자.
(아래는 그림 형태이고, 텍스트로 된 자료는 첨부된 ipynb 파일 참조)
B) 중앙값(median)
중앙값은, 자료의 값들을 크기 순서대로 나열했을 때, 가장 가운데 위치에 있는 값이다.
자료의 개수가 홀수의 경우는 가장 가운데 위치한 값 1개가 중앙값이 되고, 전체의 개수가 짝수의 경우는 가운데 2개 값에 대한 평균이 중앙값이 된다.
예를 들어, [1,2,3,4]에 대한 중앙값은, 가운데의 {2,3}에 대한 평균인 2.5가 된다.
중앙값은 Series의 median 함수로 구할 수 있다.

예제를 보자.

C) 최빈값(mode)
최빈값은 자료에서 가장 많이 있는(가장 빈번하게 관찰되는) 값이다.

예제를 통해 알아보자.

D) 최솟값, 최댓값
최솟값이나 최댓값도 자료를 대표하는 값이 될 수 있다.
고등학교의 순위를, 서울대 입학한 학생 수로 본다면, 입학한 학생수의 최댓값이 그 학교를 대표하는 것이 된다. (그렇게 순위를 매기는 것이 정당하냐 안 하냐는 차치하고)
Series에서 최솟값과 최댓값을 구하는 함수는,

사용예를 보면,

첨부 자료:
-끝-
다음 글: 1.1 대푯값 (예제)
'Information > 통계강의' 카테고리의 다른 글
| 1.3 데이터 스케일링 (이론) (0) | 2021.02.13 |
|---|---|
| 1.2 산포 (이론, 예제 풀이) (0) | 2021.02.12 |
| 1.1 대푯값 (예제 풀이) (0) | 2021.02.12 |
| 1. 통계량 (0) | 2021.02.12 |
| 0. 강의 개요 (0) | 2021.02.12 |

