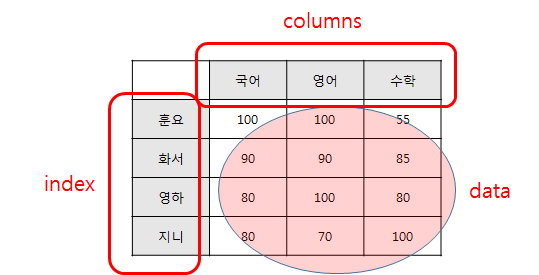
pandas 패키지의 DataFrame은 엑셀 데이터와 유사합니다.
엑셀이 가로 세로의 각 칸에 데이터가 있고, 세로축의 행과 가로축의 열이 있듯이, DataFrame도 동일한 구조를 가집니다.
- data : 실제 데이터 값들
- index: 데이터를 구분하는 값들
- columns: 데이터 항목들
아래 그림을 보면 DataFram의 data, index, columns가 뭔지 쉽게 파악이 될 것입니다.
Pandas 설치하기
Pandas도 Numpy와 마찬가지고 파이썬의 기본 라이브러리가 아니기에, 추가로 설치를 해줘야 합니다.
설치 방법은 Numpy설치 때와 마찬가지로 'pip install'을 사용하면 됩니다.
1) 윈도즈 명령어 창을 연다. : "윈도 키 + R" --> "cmd" 타이핑

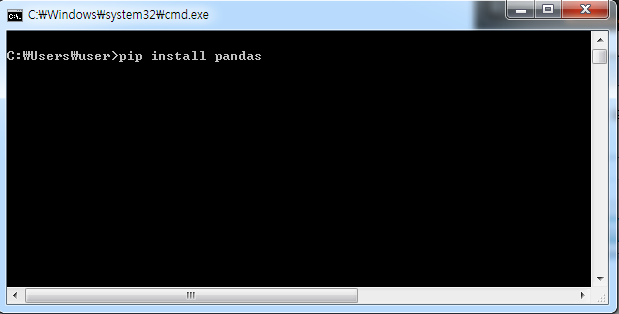
2) 'pip install pandas'라고 타이핑하고 Enter
1. DataFrame 생성
DataFrame을 생성하는 여러 가지 방법이 있습니다만, 가장 널리 사용될 수 있는 1) 리스트를 이용한 생성 2) 엑셀을 이용한 생성에 대해 알아보겠습니다.
그 외의 방법으로 '딕셔너리', 'pandas.series', 'CSV 파일', '다른 DataFrame'이 있으나, 생성 방법은 비슷하기에, 여기서 소개하는 생성 방법을 알면 바로 응용이 가능할 것입니다.
리스트를 이용한 DataFrame 생성
아래와 같은 데이터를 만들어 볼 것입니다.
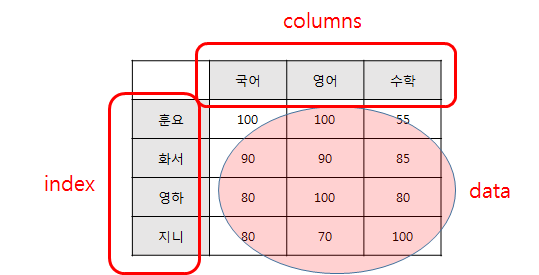
'index'와 'columns'을 지정하지 않고, data만 가지고도 DataFrame을 만들 수 있습니다.
# Pandas를 사용하기 위해서는 이렇게 import 해줘야 함
# 대부분 pandas를 pd로 축약해서 사용함
import pandas as pd
data = [
[100, 100, 55],
[90, 90, 85],
[80,100,80],
[80,70,100], #제일 뒤에 여분의 콤마가 있어도 에러가 아님
]
df = pd.DataFrame(data)
print(df)
위 코드를 실행해보면 왼쪽 세로 편에 index가 자동으로 [0,1,2,3]으로 생겼고, 위쪽에 columns도 [0,1,2]로 자동으로 생성되었습니다. 즉, DataFrame을 만들 때 'data' 부분만을 주면, 'index'와 'columns'는 자동으로 생성됩니다.
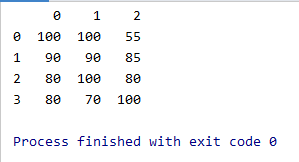
data뿐 아니라 index와 columns도 명시해서 만들어보겠습니다.
# Pandas를 사용하기 위해서는 이렇게 import 해줘야 함
# 대부분 pandas를 pd로 축약해서 사용함
import pandas as pd
data = [
[100, 100, 55],
[90, 90, 85],
[80,100,80],
[80,70,100], #제일 뒤에 여분의 콤마가 있어도 에러가 아님
]
과목 = ['국어', '영어', '수학']
이름 = ['훈요', '화서', '영하', '지니']
df = pd.DataFrame(data, index=이름, columns=과목)
print(df)
print(df.index)
print(df.columns)
print(df.values) #DataFrame의 data값 출력
위 코드의 실행 결과는,

이처럼 리스트를 data, index, columns에 지정해서 DataFrame을 만들 수 있습니다.
엑셀 데이터를 이용한 DataFrame 생성
엑셀 데이터를 읽어서 DataFrame을 만들 수 있습니다.
'pd.read_excel( )' 메서드를 이용해서 읽을 수 있으며, 엑셀 파일 이름, 시트 이름, index로 지정할 칼럼 번호, header로 사용할 행 번호를 지정하면 됩니다.
- io = "C:/tmp/성적.xlsx" : 엑셀 파일의 전체 경로 및 이름. 폴더 구분자로 '/'를 사용하는 것이 편합니다.
- sheet_name="Sheet1" : 엑셀 파일에서 읽을 시트 이름
- index_col = 0 : 인덱스로 사용할 칼럼 번호. 칼럼 번호는 0부터 시작
- header = 0 : 헤더로 사용할 Row 번호. Row번호는 0부터 시작. (DataFrame의 columns 항목이 됨)
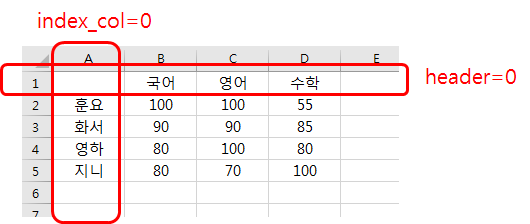
아래와 같은 엑셀 데이터를 읽어 보겠습니다.
이름을 index로 할 것이기에, index_col=0으로 해야 할 것이고,
국어, 영어, 수학이 있는 0번 Row를 column값으로 할 것이기에 'header=0'으로 할 것입니다.
read_excel을 이용할 때, DataFrame의 columns에 해당하는 것을 지정할 때 'header'를 사용하는 것에 유의. 이 'header'를 지정하지 않으면 디폴트로 첫 번째 Row가 자동 지정됨
import pandas as pd
df = pd.read_excel(io="C:/tmp/성적.xlsx", sheet_name="Sheet1", index_col=0, header=0)
print(df)여기에 사용된 엑셀 파일은,
2. 읽기
DataFrame의 데이터를 읽는 데는 여러 가지 방법이 있으나 여기서는 3가지 방법만을 소개하고, 이 3가지 방법이면 사용하는데 불편이 없을 것입니다.
- index와 columns를 직접 이용해서: df['국어'], df['훈요':'영하']
- df.loc[인덱스 범위, 칼럼 범위]: df.loc['화서':'영하', '영어']
- df.iloc[인덱스번호 범위, 칼럼번호 범위]: df.iloc[0:1, 2:2]
index와 columns를 직접 이용해서
대괄호 안에 1) 칼럼명 2)인덱스 명 범위 3)인덱스 번호 범위를 넣어서 값을 읽을 수 있습니다.
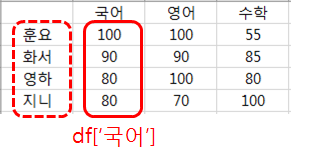
'국어' 점수를 모두 읽는다면, 칼럼명 '국어'를 이용하면 됩니다.
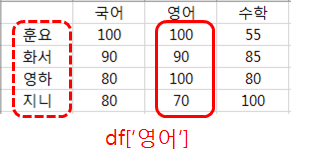
'영어' 점수를 모두 읽는다면, 칼럼명 '영어'를 이용하면 됩니다.
'훈요'의 점수를 모두 읽는다면, 인덱스 이름 범위를 '훈요':'훈요'로 하거나, 인덱스 번호 범위를 0:1로 합니다.
'행'에 해당하는 '인덱스'를 이용할 때는, 칼럼과 달리 '범위'로 지정함에 유의합니다.
인덱스 이름으로 할 때는 df[시작 이름 : 끝 이름]이고, 인덱스 번호로 지정할 때는 df[시작 번호 : 끝 번호 + 1]을 사용합니다.
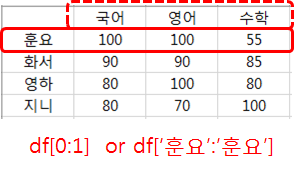
'화서'와 '영하'의 점수를 읽는다면,
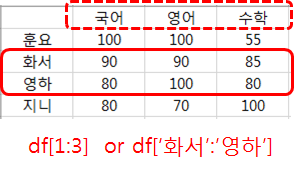
df.loc[인덱스 범위, 칼럼 범위]
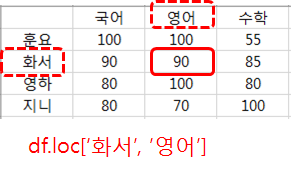
df.loc의 사용법은, 대괄호 사이에 '인덱스의 범위'와 '칼럼 범위'를 지정해서 값을 읽습니다.
'화서'의 영어 점수를 가져오려면 df.loc['화서', '영어']
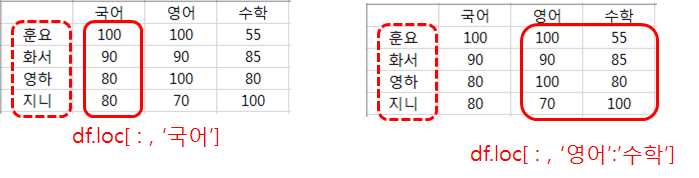
'훈요'의 국어/영어/수학 점수 전체를 읽으려면 df.loc['훈요']
'화서'와 '영하'의 점수 전체를 읽으려면 df.loc['화서':'영하']

'국어' 점수 전체를 읽으려면 df.loc[ : , '국어']
'영어'와 '수학' 점수 전체를 읽으려면 df.loc[ : , '영어':'수학']
지금까지 설명한 df.loc의 사용법에 대한 테스트 코드입니다.
import pandas as pd
df = pd.read_excel(io="C:/tmp/성적.xlsx", sheet_name="Sheet1", index_col=0, header=0)
점수=df.loc['화서','영어']
print('화서의 영어점수\n', 점수)
print()
점수 = df.loc['훈요']
print('훈요의 점수\n', 점수)
print()
점수 = df.loc['화서':'영하']
print('화서:영하의 점수\n', 점수)
print()
점수 = df.loc[:,'국어']
print('국어 점수\n', 점수)
print()
점수 = df.loc[:,'영어':'수학']
print('영어,수학 점수\n', 점수)
print()
점수 = df.loc['훈요':'화서','국어']
print('훈요와 화서의 국어 점수\n', 점수)
print()
점수 = df.loc['화서':'영하','영어':'수학']
print('화서와 영화의 영어,수학 점수\n', 점수)df.iloc(인덱스번호 범위, 칼럼번호 범위)
df.iloc는 df.loc와 사용법과 이름 대신 번호를 사용한다는 점만 빼고는 똑같습니다.
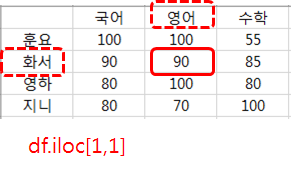

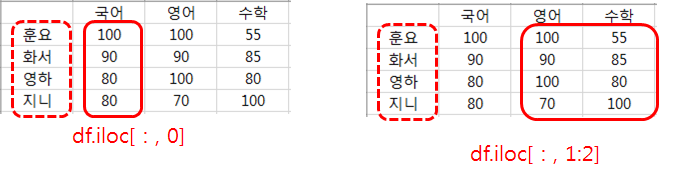
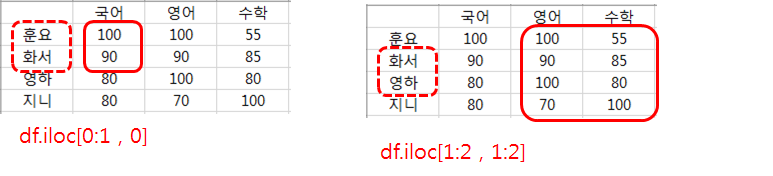
조건을 만족하는 데이터만 가져오기
수학 점수가 80점 이상인 학생의 데이터만 얻어내려면, '수학' 열의 값에 대해 조건식을 걸어서 값을 가져오면 됩니다.
df[df['수학'] >= 80] 혹은 df[df.loc[ : , '수학']]
수학우등생 = df[df['수학'] > 80]
print('수학우등생\n', 수학우등생)
국어우등생 = df[df.loc[:,'국어'] > 80]
print('국어우등생\n', 국어우등생)
수학영어우등생 = df[(df['수학'] > 80) & (df['영어'] > 80)]
print('수학영어우등생\n', 수학영어우등생)
3. 수정/추가
기존 데이터에 대한 수정은, 위에서 살펴본 '읽기'때와 마찬가지로 df.loc와 df.iloc를 이용해서 하면 됩니다.
추가는 df.loc를 이용합니다.
데이터 수정
'훈요'의 '국어' 점수를 80으로 바꾸려면,
df.loc['훈요','국어'] = 80 혹은 df.iloc[0,0] = 80
'화서'의 국/영/수 점수 모두를 100점으로 바꾸려면,
df.loc['화서'] = [100,100,100] 혹은 df.iloc[1] = [100, 100, 100]
행 추가
'태양'이라는 학생의 점수를 추가하려면,
df.loc['태양'] = [10,20,30]
위에서 설명한 '수정'관련한 테스트 코드입니다.
import pandas as pd
df = pd.read_excel(io="C:/tmp/성적.xlsx", sheet_name="Sheet1", index_col=0, header=0)
print(df)
df.iloc[0,0]=80
print(df)
df.iloc[1,] = [100,100,100]
print(df)
df.loc['태양'] = [10,20,30]
print(df)
4. 삭제
삭제는 drop(인덱스 이름)을 사용합니다.
'화서'의 데이터를 모두 삭제하려면,
df.drop('화서')
조건식을 걸어서 삭제하고자 할 때는, 해당 조건식에 맞는 index명을 찾아서 dfdrop(인덱스 이름들)로 합니다.
만약, 수학 점수가 80점 미만인 모든 학생을 삭제한다면,
수학점수낮은학생들 = df[df['수학'] < 80]
idx = 수학점수낮은학생들.index
df2 = df.drop(idx)
print(df2)
-끝-
다음글: 04-6. 데이터이용한 그래프 그리기
목차로 이동: [목차]CxO를 위한 코딩 강좌(파이썬을 중심으로)
'Programming > CxO를 위한 코딩' 카테고리의 다른 글
| 04-4 배열(numpy.array) (4) | 2020.06.25 |
|---|---|
| 04-4 집합(set) (0) | 2020.06.25 |
| 04-3 튜플(tuple) (0) | 2020.06.25 |
| 04-2 딕셔너리(dict) (0) | 2020.06.25 |
| 04-1 리스트(list) (0) | 2020.06.25 |
