컴퓨터에서 소리를 담는 가장 기본적인 파일 구조가 WAV 파일 구조이다.
1999년 경부터 Microsoft와 IBM에 의해 파일 구조가 정의되어 사용되었고, PCM 방식으로 인코딩 된 디지털 신호를 압축되지 않은 형태로 가지고 있다.
WAV 파일 자체는 압축도 지원한다고 하는데, 내가 본 적은 없다. 일반적으로 WAV 파일은 압축하지 않은 날것 그대로의 PCM 데이터 덩어리로, 해서, 파일 사이즈가 매우 크다.
WAV 파일의 상세구조는 여기에 잘 정리되어 있다.
간략하게 핵심만을 테이블로 정리하면 아래와 같다.
| Offset | Length | Field Name | Contents | Endian | Example |
| 0 | 4 | Chunk ID | "RIFF"=0x52494646 | Big | 52 49 46 46 |
| 4 | 4 | Chunk Size | 전체 파일크기 - 8 | Little | 24 08 00 00 = 0x0824=2084 |
| 8 | 4 | Format | "WAVE"=0x57415645 | Big | 57 41 56 45 ="WAVE" |
| 12 | 4 | SubChunk1 ID | "fmt"=0x666d7420 | Big | 66 6d 74 20 = "fmt" |
| 16 | 4 | SubChunk1 Size | 16 for PCM | Little | 10 00 = 16 |
| 20 | 2 | Audio Format | PCM=1 | Little | 01 00 = 1(PCM) |
| 22 | 2 | Num Channels | Mono=1, Stereo=2 | Little | 02 00 =2 (Stereo) |
| 24 | 4 | Sample Rate | 8000, 14000 etc | Little | 22 56 00 00 = 22,050 |
| 28 | 4 | Byte Rate | Sample Rate * NumChannels * BitPerSample/8 | Little | 88 58 01 00 = 88,220 = 22050 * 2 * 16 / 8 |
| 32 | 2 | Block Align | NumChannels * BitsPerSample/8 | Little | 04 00 = 4 = 2 * 16/8 = 4 |
| 34 | 2 | Bits Per Sample | 8 bits =8, 16 bits = 16, etc | Little | 10 00 = 16 |
| 36 | 4 | SubChunk2 ID | "data"=0x64617461 | Big | 64 61 74 61 = "data" |
| 40 | 4 | SubChunk2 Size | NumSamples * NumChannels * BitsPerSample/8 | Little | 00 08 00 00 =0x0800 = 2048 |
| 44 | * | Data | The actual sound data | Little | - |
각 항목별로 주요 사항만 알아보자.
I. Wave File Header - RIFF Type Chunk
마이크로 소프트웨어사는 RIFF(Resource Interchange File Format)라는 표준 파일 형식을 만들고, 영상압축/오디오 파일 등에 적용해서 사용하고 있다. WAV 파일도 RIFF 파일 표준을 따르고 있기에, WAV 파일의 가장 앞부분은 RIFF의 표준에 맞는 정보가 들어 있고, 그 정보는 Chunk ID, Chunk Size, Format
1) Chunk ID (4 바이트)
RIFF에서는 데이터의 덩어리를 'Chunk'라고 부른다. 오디오 형식 Chunk, 오디오 데이터 Chunk, 영상 데이터용 Chunk 등
WAV 파일의 경우 Chunk ID="RIFF"=0x52494646로 고정되어 있다.
2) Chunk Size (4 바이트)
WAV 파일의 전체 크기가 적혀 있다. Chunk ID 4바이트와 Chunk Size 4바이트를 제외한, 나머지 파일 크기이다.
Chunk Size = 전체 파일크기 - 8
3) Format (4 바이트)
RIFF의 Format을 나타내는 것으로, WAV 파일의 경우는 "WAVE"라는 값으로 고정
"WAVE"이 아스키 값은 0x57415645
II. Format Chunk
Format Chunk에는 이 WAV 파일의 데이터를 어떻게 읽어서 오디오로 재생할 지에 대한 모든 정보가 담겨 있다.
1) SubChunk1 ID (4 바이트)
RIFF 타입 파일은 여러 개의 Chunk를 가질 수 있고, 각 Chunk마다 ID와 Size가 명시된다.
RIFF 타입 Chunk 이후에 처음 나오는 Chunk여서, SubChunk1이라고 임의로 이름을 붙인 것이다.
여하튼, WAV 파일에서 RIFF Chunk 이후에 처음 나오는 Chunk는 오디오 데이터를 해석할 수 있는 Format 정보를 담는 Chunk이고, Chunk ID = "fmt "=0x666d7420으로 고정되어 있다. ( "fmt "에서 글자 fmt뒤에 공백 문자가 있음에 유의. 즉 4바이트 정보이다.)
2) SubChunk1 Size (4 바이트)
SubChunk1의 크기.
ID 4바이트와 Size용 4바이트를 제외한 크기이다.
일반적으로 WAV 파일은 비압축 형태이고, 이 경우 SubChunk1 Size = 16이다. 그런데 WAV 파일의 오디오 데이터가 압축 형태이면 "Extra format bytes"에 압축 관련한 정보가 들어 있고, 이 경우 SubChunk1 Size는 16보다 크게 된다.
3) Audio Format (=Compression Code) (2 바이트)
일반적으로 값 "1"을 가지며, 이는 비압축인 PCM 포맷을 의미

4) Num Channels (2 바이트)
음성 파일의 채널 수,
모노라면 1, 스테레오라면 2
5) Sample Rate (4 바이트)
1초 당 샘플링한 횟수.
8000이면, 오디오 신호에 대해 1초당 8천 번에 걸쳐 디지털 값으로 변환한 것
만약 8kHz(=8,000Hz)로 샘플링했다면, 나이퀴스트 이론에 의해서, 4kHz 이상의 소리에 대해서는 제대로 샘플링할 수 없음.
사람의 가청 주파수가 20~20kHz이기에 40kHz 이상으로 샘플링해야 사람이 듣는 모든 소리를 디지털 화할 수 있음. 해서, 주로 44.1kHz로 샘플링함 (CD의 경우)
6) Byte Rate (4 바이트)
1초 동안의 소리에 해당하는 바이트 수
이 값은 3가지 정보에 의해서 결정됨: a) Sample Rate b) Num Channel c) BitPerSample
1초당 8000번 샘플링하고(Sample Rate=8,000), 채널은 Mono(Num Channel=1), 디지털 값을 표현하는 데 2바이트씩 사용했다면(BitPerSample=16) --> 1초 동안의 소리 데이터는 8,000 * 1 * 2 = 16,000 바이트 필요
이처럼 Byte Rate 정보는 3가지 정보를 조합해서 계산해낼 수 있지만, WAV 파일을 만들 때 결정될 수 있는 값이기에, 다시 계산하지 않아도 되도록 Byte Rate에 명시한 것임
7) Block Align (2 바이트)
소리 데이터 블록 크기를 의미
만약 NumChannels=2로 스테레오 타입으로 녹음이 되었다면, 같은 시점에서 소리 데이터가 2개가 존재하게 됨. 그리고 만약 데이터의 표현을 2바이트씩 한다면, 소리 데이터 한 블록의 크기는 4바이트가 된다.
이 데이터도 NumChannels와 BitsPerSample 값을 이용해서 계산될 수 있으나, 파일 생성 시 결정되는 값이기에 따로 명시한 것임. 데이터를 읽어 나갈 때 Block Align 단위로 데이터를 읽어 나가면, 각 소리(sound) 값 단위로 되는 것임.
8) Bit Per Sample (2 바이트)
소리 신호를 샘플링하여 디지털 숫자로 나타낼 때, 몇 비트를 사용해서 나타냈는지의 값
만약 8이라면, 소리 값을 0~255까지의 수로 나타낸 것.
이 값이 클수록, 소리의 크기를 세밀하게 구분해서 표현한 것이기에, 음질(소리의 깊이)이 좋아짐. 보통 16을 사용
III. Data Chunk
실제 오디오 신호 값에 해당하는 디지털 값을 저장한 부분
1) SubChunk2 ID (4 바이트)
ID는 "data"=0x64617461
2) SubChunk2 Size (4 바이트)
Data 부분의 크기
3) Data
실제 오디오 신호에 대한 디지털 값
Block Align 크기가 한 시점에서의 소리 값임(NumChannels=2라면, 절반은 left 채널용 값이고 나머지 절반은 rigtht 채널용 값)
Data가 몇 초 동안의 소리일까는, Data Size를 Byte Rate로 나눠주면 됨 (Byte Rate가 1초 동안의 데이터 크기를 나타내는 값이기에)
실제 WAV 파일을 바이너리 편집기를 이용해서 오픈 후, 각 데이터를 WAV 파일 포맷과 비교하면서 살펴보자.
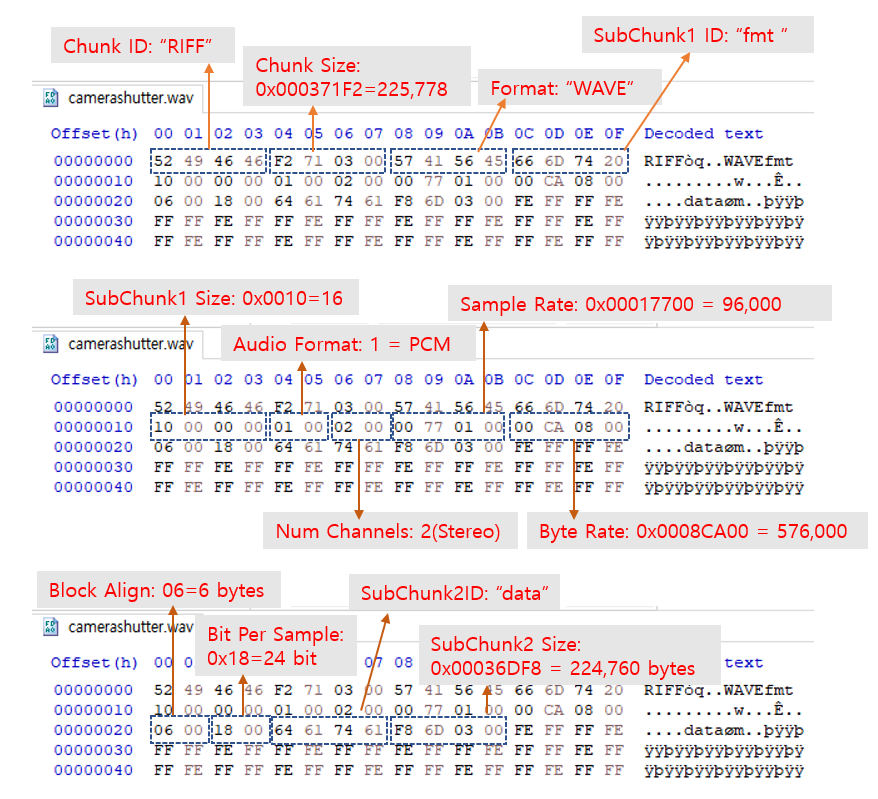
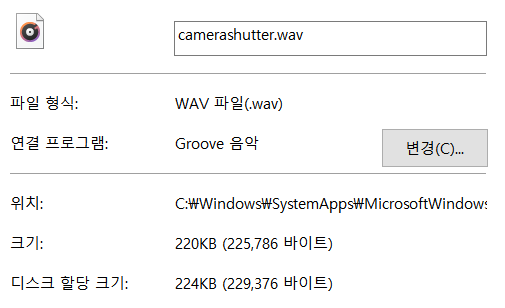
위 샘플은 1초도 안 되는 데이터인데 파일크기가 225,786 바이트이고, 이는 WAV 파일 내부의 Chunk Size = 225,778 바이트와도 일치한다. (225,778 + 16 = 225,786)
사이즈가 이렇게 커진 데에는 Sample Rate를 96,000으로 했고(CD 품질에 2배), 하나의 값에 대한 표현도 24 bit로 매우 세밀하게 했기 때문이다.
이 페이지의 목적은, WAV 파일을 어떻게 핸들링할지의 기초로, WAV 파일의 구조를 아는 데 있었다.
비교적 간단한 형태의 구조이고, 헤더에 있는 몇 가지 데이터만 읽은 후, 나머지는 실제 소리 데이터를 쭈욱 읽어내면 된다.
다음 페이지에는 이 WAV 파일 구조를 이용해서, 실제 WAV 파일을 Excel에서 읽어내는 프로그램을 짜 볼 것이다.
-끝-
'푸리에 변환, 신호 > 소리 신호' 카테고리의 다른 글
| 02. 엑셀로 WAV 파일 읽기 (6) | 2022.07.27 |
|---|
